Topic Scene Graph Generation by Attention Distillation from Caption
Abstract
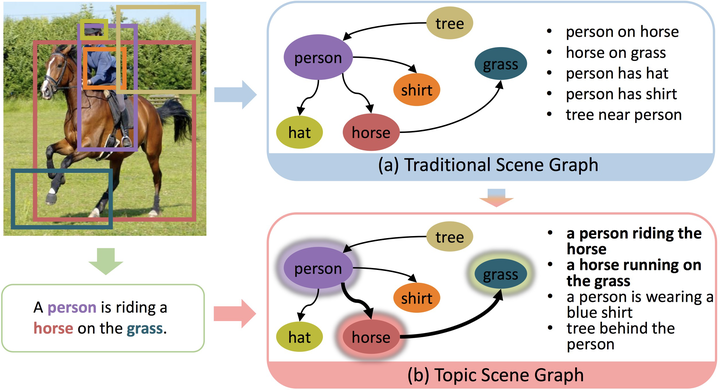
If an image tells a story, the scene graph and image caption are the most popular narrators. Generally, a scene graph prefers to be an omniscient generalist, while the image caption is more willing to be a specialist, which outlines the gist. Lots of previous studies have found that as a generalist, a scene graph is not enough to serve for downstream advanced intelligent tasks unless it can reduce the trivial contents and noises. In this respect, the image caption is a good teacher. To this end, we let the scene graph borrow the ability from the image caption so that it can be a specialist on the basis of remaining all-round, resulting in the so-called Topic Scene Graph. What an image caption pays attention to is distilled and passed to the scene graph for estimating the importance of partial events (relationships). In addition, as this attention distillation process provides an opportunity for combining the generation of image caption and scene graph together, we further transform the scene graph into linguistic form by sharing a single generation model with image caption, making the scene graph with rich and free-form expressions. Experiments show that the attention distillation brings significant improvements on mining important relationships and demonstrate its potential for precise and controllable cross-modal retrieval.