Sketching Image Gist: Human-Mimetic Hierarchical Scene Graph Generation
Abstract
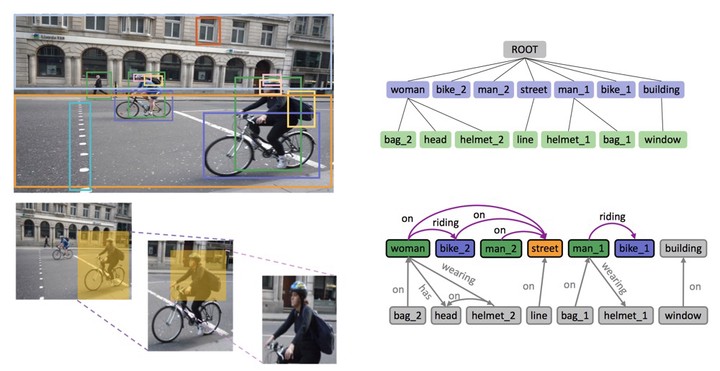
Scene graph aims to faithfully reveal humans’ perception of image content. When humans analyze a scene, they usually prefer to describe image gist first, namely major objects and key relations in a scene graph, which contains essential image content. This humans’ inherent perceptive habit implies that there exists a hierarchical structure about humans’ preference during the scene parsing procedure. Therefore, we argue that a desirable scene graph should be also hierarchically constructed, and introduce a new scheme for modeling scene graph. Concretely, a scene is represented by a human-mimetic Hierarchical Entity Tree (HET) consisting of a series of image regions. The levels of HET reflect the perception priority level of humans. To generate a scene graph based on HET, we parse HET with our designed Hybrid Long Short-Term Memory (Hybrid-LSTM) network which specifically encodes hierarchy and siblings context to capture the structured information embedded in HET. To further prioritize key relations in the scene graph, we devise a Relation Ranking Module (RRM) to dynamically adjust their rankings by learning to capture humans’ subjective perceptive habits from objective entity saliency and size. Experiments are conducted on VRD, Visual Genome (VG), and VG-KR dataset (an extended version of VG we create by adding indicative annotations of key relations). Results demonstrate that our method not only achieves state-of-the-art performances for scene graph generation, but also is expert in mining image-specific relations which play a great role in serving downstream tasks.